Data Lake Houses: Getting Your Bank Data Right

In wrestling, there are hundreds of thousands of moves to learn. You will fail if you try to learn them all early in your wrestling career. Moves come with experience. Concepts come first. To start, what is essential is conditioning and learning about angles. Defending your angles and using angles to attack. When it comes to future success in data management in banking, the same rules apply. Your strength is your data, and your success comes from defending your data and applying your data at various angles – to credit, fraud, marketing, and understanding both your employees and customers. This article breaks down what bank executives need to know about data management, building strength, and applying the angles to achieve success. We will look in-depth at data lake houses and suggest why your bank may want to consider one, no matter the bank’s size.
Capital Is Cheap. Data Is Expensive
A bank can quickly raise capital, but the ability to leverage its data is fast becoming the difference between an average bank and a top-performing bank. While your bank can raise capital in a matter of months, leveraging data takes years. Therefore, it is imperative for every bank to start thinking about the value of their data and how they are doing to manage it from an enterprise-wide perspective.
Because “data is the new oil,” it makes sense that banks of all sizes need to invest in where and how they store their data. The smaller the bank you are, the easier and cheaper data management is. Most data services charge by the amount of storage and processing power applied. Thus, the data cost for a small bank is relatively the same as a large bank. While it is true that a larger bank may have more uses for its data and be able to scale faster, the returns for all banks are likely in the mid-double digits and likely the triple digits.
The sooner a bank works on it, the more data that can be captured and the more value the bank will become. Tesla is a stark example of this.
While other electric car manufacturers have approached Tesla’s car and battery performance, there is not a car company that is close to having the amount of data Tesla has to enable self-driving cars. Tesla is poised to dominate self-driving because of the size of its data set available for training. This will make Tesla’s algorithms multiple times better than the next closest competitor.
The Database
No doubt you are familiar with a database. Your bank has lots of them. You have several in your core system, likely some for online/mobile banking and another hundred or so in various applications. A database is perfect for quickly accessing and mathematically processing specific sets of information such as deposits, payments, mortgages, or commercial loans. This data can be “structured,” such as a customer’s current deposit balance, or “unstructured,” such as loan documents or social media posts.
The problem is threefold. First, your data is all over the place and hard to access. Second, since you have multiple databases, you likely have the same information with different qualities, each named something different. One data model will have it as “Account owner,” another as “Customer Name,” while others will have “Customer First” and “Customer Last.” In short, the strength of your data is likely that of a middle school wrestler.
The third largest problem is that a database is designed to house, store and retrieve information. A database isn’t particularly good at analytics.
Luckily, all three challenges are solved by a data warehouse.
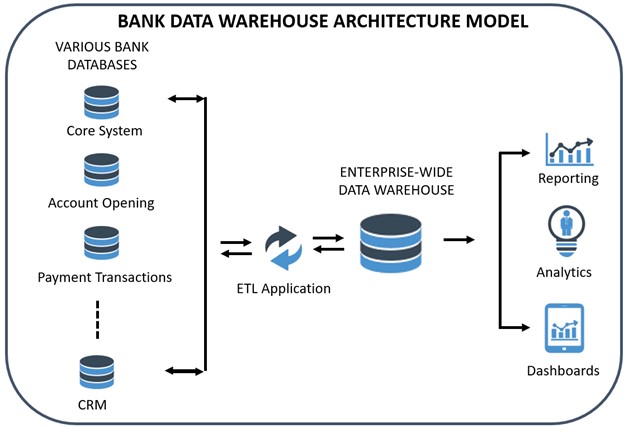
What Is a Data Warehouse?
A data warehouse is a layer that allows your bank to connect to multiple databases. The warehouse will enable you to extract, transform and load (an “ETL” process) your data into a central repository and allows you to run analytics on the data efficiently. We use “ETL” generically as it includes the extract, load, and transform process (“ELT”), which is more modern, scalable, and more common for data lake houses.
For example, suppose you store the “Street Address” as a single field composed of the house number and the customer’s street. In that case, you can reconcile that with another database that stores that address information in two separate fields – “Street Number” and “Street Name.” Using a data warehouse can fix all these problems and aggregate your data from multiple locations.
A data warehouse is suitable for cleaning, organizing, and analyzing. As we say, a database is where the work gets done (i.e., transaction processing), and the data warehouse is where the work gets seen.
The most popular data warehouses for banks are all cloud-based: Google Big Query, Amazon Redshift, Azure SQL Data warehouse, and, our favorite, Snowflake.
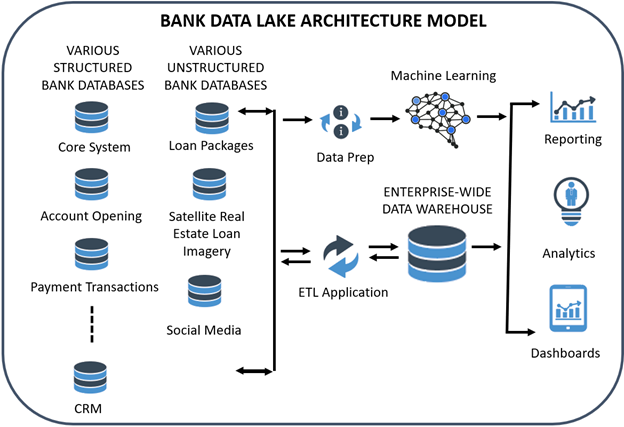
What is a Data Lake?
The problem arises that a bank often has a bunch of information, say customer financials, that it knows are important but doesn’t yet know how to deal with because these financials are in different formats and forms. While it could store these financials using some methodology, such as creating a file on a server under the customer’s name, the information within those financials would be challenging to access.
The alternative is to dump customer financials into a “data lake,” a storage area for “unmapped” data. A data lake can handle structured, unstructured, and raw data where the data might not have a “schema” or blueprint.
In our customer financial example, a bank may hire an information specialist to create code that will read each document, separate financials into years, break the information into specific fields, and create a schema all on demand (called a “schema-on-read”). A banker may then want to import this data from its data lake to its data warehouse within a specific data model. The command might pull out “2020 revenue” by looking through Word, PDFs, CSV files, and Excel spreadsheets and then populating that data so it can be automatically analyzed.
Sometimes, a bank receives data and doesn’t know what to do with it. A bank might get a download of data from the SBA on its Paycheck Protection Program performance or credit card data from its third-party processor. A bank might have nowhere to store it, so that it would sit in a file somewhere on a server. The data lake is the perfect place to store this information for easier access.
One popular example is that many banks are doing device checks during mobile account opening to ensure the mobile device is registered to the customer. A bank’s vendor usually hires a third-party data provider to check the device, and once confirmed, the bank likely doesn’t do anything with that device information. However, this is precious information.
Banks will soon be using device information across various uses to include identity in the branch, real-time payment transactions, or loan transactions. Instead of paying for the information each time, a bank may decide to store this information in its data lake so that it may use it across products. A bank could then ingest the device information into the customer record in the data warehouse in the future, or it may want to conduct machine learning on the raw data to validate device age and fraud, for example.
Banks use most of the previously mentioned data warehouse providers, such as Google, Microsoft, and Amazon, which also have data lake capabilities.
What Are Data Lake Houses?
Over the last two years, banks have migrated to a “data lake house.” A data lake house combines a data lake and a warehouse. It allows for the inexpensive storage of data like a data lake but has some features of a database or data warehouse that allow for speed, redundancy, and stability. This all makes processes like ETL faster, allows for more efficient machine learning, and makes more data available to the business line.
While it is tempting to think of a data lake as a combination of a data lake and a warehouse, it is more than that because the combination is now integrated. With a data lake and a data warehouse, you had two different storage areas plus an array of tools that interacted with each. As bankers often found, one tool would grab the data from the data warehouse, store it separately in a “data mart,” and then create a report. As the data changed in the originating database, it would take time for the data to be updated in the warehouse and then in the cashed data for the reporting application.
That latency could be 24 hours when dealing with deposit balance or payment information. In an era with account opening in five minutes and real-time payments in seconds, this lag started to create problems for banks. Further, because a data lake house is more scalable and has open access, banks can run it at a fraction of the cost and risk.
A lake house is not only a central storage area but also has the tools such as machine learning models, data science tools, reporting, dashboarding, and visualization that can easily integrate into the combined platform. Banks can use the lake house vendor’s machine learning tools native to the lake house or use prebuilt connections for quick and secure integrations.
While it used to take a bank $5B in asset size to afford a data warehouse and lake, a bank of $1B in asset size can take advantage of a lake house.
A current widespread use case for a bank utilizing a data lake is to house streaming market data such as the SOFR index or other interest rates. Further, some banks are housing economic data in their data lake house.
Previously, most banks had their data warehouse designed around customer data. Meanwhile, their data lake held random data for future analysis. With a data lake house, the bank efficiently stores the streaming data in the lake house. It then can correlate various interest rate indices and economic data to items like deposit balances, credit delinquencies, or profitability.
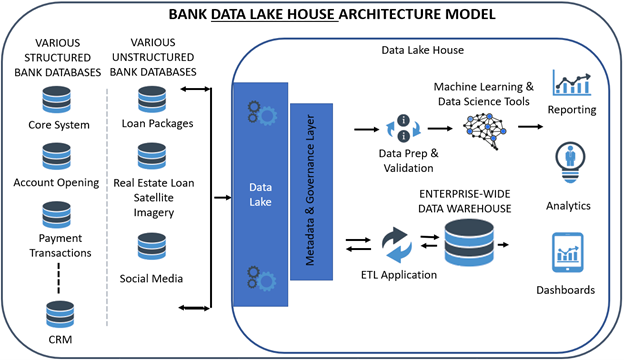
For banks, the most popular data lake houses are Databricks and Snowflake.
Putting This into Action
The key takeaway here is that banks should look at platforms where they are able to load any type of data at scale and effectively transform plus enrich the data. Given the changes that have occurred in the past ten years (cloud access, the cheapness of storage, etc.), replicating and centralizing data access into a cloud-native platform is now within the reach of all banks. Old data warehouse projects would start with the IT department spending six months to build servers is a thing of the past. Modern platforms now offer computing and storage power on demand. This allows banks more capabilities, greater efficiency, and the ability to run multiple data workloads simultaneously. Now, multiple departments can run analytical queries against the same datasets without impacting performance.
A data lake house can help your bank wrestle your data in order to get it in the shape of an Olympic athlete. Data lake tools have never been easier to use and often are available for the business line. By creating greater availability of clean data, bankers will find a myriad of angles from which to apply data science and machine learning. Like wrestling, the journey to mastery starts with concepts.
A data lake house leapfrogs the limitations of a data warehouse due to its ability to manage all types of data while managing security, efficiency, machine learning, and workflow natively. It takes a lake or even an “ocean” of data and creates an open system to manage it and support any use case a banker can dream up. Whether it is numbers, narrative, an audio stream, video, or some other data source yet to be invented, a data lake house is built to handle it.